





I. Problématique▲
Il peut arriver qu'un fichier de base de données ait été corrompu par un problème matériel (fichier corrompu, disque abîmé, bug d'un contrôleur disque, etc.).
Soulignons le fait que certaines des commandes qui vont suivre sont extrêmement intrusives. Il convient donc d'avoir une bonne connaissance du moteur de la base avant de se lancer dans une telle démarche.
La procédure officielle de récupération de données après un crash est de remonter une sauvegarde effectuée précédemment. Il se peut malheureusement que les sauvegardes précédentes aient déjà été corrompues. D'expérience, il apparaît que peu de DBA exécutent les commandes de vérification de validité (dbcc checkdb, dbcc checkalloc, dbcc checkcatalog) de la base avant d'exécuter les sauvegardes. La mise en place d'une stratégie permettant de minimiser les temps morts d'un moteur (sauvegardes, réplications,haute disponibilité, etc.) est la pierre angulaire d'une environnement stable, mais cette partie ne sera pas couverte ici.
Une autre source importante permettant de résoudre un certain nombre d'erreurs et le Troubleshooting and Error Messages Guide.
Cette procédure a été validée sur un serveur Sybase ASE version 12.x.
La plupart des tables de Sybase ASE sont, de manière interne, stockées sur des pages de données liées entre elles par des pointeurs.

La plupart des erreurs dues à une mauvaise allocation peuvent être résolues en exécutant un simple dbcc avec son option fix en mode monoutilisateur. Ces commandes résolvent la plupart des erreurs relatives à l'entête de la page de données, mais ne fixent pas les corruptions relatives aux données stockées sur la page qui auraient pu être corrompues.
Ce n'est par compte plus le cas pour les pages DOL (Data Only Locking) - optionnelles dès Sybase ASE 11.9.2 - permettant de modifier le schéma de verrouillage d'une table. Leurs pointeurs répondent à d'autres règles et une récupération s'avère bien plus périlleuse puisque le chaînage n'est plus garanti. On ne peut alors trouver l'ordre des enregistrements qu'en se référant aux unités d'allocation (via DBCC allocdump(dbid¦nom de la base, no de la page d'allocation)) et, le temps échéant, en allant rechercher le contenu des pages qui peut se trouver être un pointeur sur une autre page… Le casse-tête même pour des experts…
II. Accéder à la base corrompue▲
Si vous vous amusez à lire ce type d'article, c'est que vous savez passer d'une base a l'autre sur un serveur de données de type Sybase ASE ou Microsoft SQL Server (pre-2000). Oui, bien sûr, il s'agit de cette simple commande use NomDeBase. Si cette commande marche, vous pouvez directement passer plus bas.
Mais que ce passe-t-il si la base, lors du dernier redémarrage du serveur, n'a pas pu être mise en ligne compte tenu de son état corrompu ?
Avant tout, il faut donc pouvoir accéder à cette base malgré ses problèmes. Il va nous falloir attaquer la table système master..sysdatabases comme suit :
sp_configure 'allow updates', 1
go
select status, status-256 -- à garder pour usage ultérieur
from master..sysdatabases
where id=db_id('MaBaseCorrompueEtInnaccesible')
go
update master..sysdatabases
set status=-32768
where id=db_id('BaseInnaccesible')
go… et redémarrer le serveur. Ce flag -32768 permet de remonter la base sans passer par sa phase de recovery. Autant dire qu'elle sera accessible, mais dans un état des plus instables.
III. Trouver les informations nécessaires▲
|
Information |
Comment la trouver |
Résultat |
|---|---|---|
|
Nom du serveur |
select @@servername |
ASE125 |
|
Nom de la base de données |
select db_name() |
test |
|
ID de la base |
select db_id(« test ») |
5 |
|
ID de l'objet corrompu |
Spécifié(objid) dans l'errorlog lors de l'apparition de l'erreur ou dans un résultat d'un dbcc |
1148528094 |
|
Type de table |
sp_help PERSONNE |
Table utilisateur heap, sans partition, verrouillage APL |
|
Script de création de la table et de ses index, ses contraintes, etc. |
DDLgen ou n'importe quel outil de Reverse Engineering |
Recherchons ensuite les informations concernant le début du chaînage de la table
Select indid, first, root, name
from sysindexes
where id = object_id('PERSONNE')
indid first root name
------ ----------- ----------- -----------------------------
1 849 864 PERSONNE_11485280941
255 633 633 tPERSONNE
sp_helpartition PERSONNE -- partitionnée juste pour cet exemple
go
partitionid firstpage controlpage ptn_data_pages
----------- ----------- ----------- --------------
1 849 1412 229
2 617 616 1
3 761 760 1
4 1417 1416 1
Partitions Average Pages Maximum Pages Minimum Pages Ratio (Max/Avg)
----------- ------------- ------------- ------------- ---------------
4 133 529 1 3.977444
select partitionid, firstpage from syspartitions where id= 1148528094
go
partitionid firstpage
----------- ---------
1 849
2 617
3 761
4 1417Si l'indid de l'erreur est situé entre les valeurs 2 et 254, il suffit alors
- de rechercher l'index incriminé ;
- de le supprimer ;
- et de le recréer.
Ici s'arrêterait la démonstration.
IV. La méthode▲
Dans le cas d'une corruption en indid = 1 ou 0, passons directement plus bas.
Dans celui d'une corruption de page de texte ou d'image (indid = 255), la méthode s'applique de la même manière, mais il faut déterminer le début de chaînage du champ. Pour trouver la 1re page de ce chaînage, il suffit d'exécuter la commande suivante :
dbcc traceon(3604)
go
dbcc pglinkage(5, 638, 0, 2, 0, 0)
go
Object ID for pages in this chain = 1148528094.
Page : 638
Page : 635
Beginning of chain reached.
2 pages scanned. Object ID = 1148528094. Last page in scan =635.
Ensuite, pour connaître la ligne incriminée, passons la valeur trouvée
Select ID_pers
from PERSONNE
where convert(int, textptr(Photo))=635
ID_pers
--------
4Vérifions le lien des pages de cette table à l'aide des commandes dbcc pglinkage et dbcc page. Notons que pour éviter de pousser en avant les corruptions, il serait bon de bénéficier de l'accès exclusif de la base (ou en tout cas de la table) incriminée.
use test
go
dbcc traceon(3604) -- envoie les résultats à l'écran
go
dbcc page (5, 1396,0, 0) -- affiche la page corrompue en la lisant sur le disque (et pas en cache)
go
Page read from disk.
BUFFER:
[...]
PAGE HEADER:
Page header for page 0x214C5800
pageno=1396 nextpg=1397 prevpg=1395 objid=1148528094 timestamp=0000 000132a0
nextrno=31 level=0 indid=0freeoff=1969 minlen=42
page status bits: 0x101 (0x0100 (PG_ADDEND), 0x0001(PG_DATA))Le résultat obtenu nous retourne les pointeurs sur la page suivante (nextpgs) et la page précédente (prevpgs) du chaînage. Nous répétons cette commande sur ces deux autres pages :
dbcc page (5, 1395)
dbcc page (5, 1397)
go
[...]
PAGE HEADER:
Page header for page 0x21509800
pageno=1395 nextpg=1396 prevpg=1394 objid=1148528094timestamp=0000 0001327d
nextrno=31 level=0 indid=0 freeoff=1970 minlen=42
page status bits: 0x101 (0x0100 (PG_ADDEND), 0x0001(PG_DATA))
[...]
PAGE HEADER:
Page header for page 0x21509800
pageno=1397 nextpg=1398 prevpg=1396 objid=1148528094timestamp=0000 000132c3
nextrno=31 level=0 indid=0 freeoff=1970 minlen=42
page status bits: 0x101 (0x0100 (PG_ADDEND), 0x0001 (PG_DATA))Le but est de déterminer si ces deux pages sont correctes, si elles pointent sur le même objet : comparons donc scrupuleusement les objid et indid, si le chaînage est correct (ce qui est le cas dans cet exemple précis). Remarquons qu'il ne s'agit que d'un hasard si le chaînage semble se suivre (1394 -> 1395 -> 1396 -> 1397 -> 1398). Ceci étant fait, nous pourrons alors essayer de récupérer la majeure partie des données de la table en évitant la page incriminée :
-- le dernier chiffre détermine la direction: 0 = en arrière; 1 = en avant
dbcc pglinkage (5, 1395,0, 1, 0, 0)
dbcc pglinkage (5, 1397,0, 1, 0, 1)
go
Object ID for pages in this chain = 1148528094.
Beginning of chain reached.
Page : 896
Page : 895
Page : 894
Page : 893
Page : 892
Page : 891
Page : 890
Page : 889
Page : 888
Page : 855
Page : 854
Page : 853
Page : 852
Page : 851
Page : 850
Page : 849
513 pages scanned. Object ID = 1148528094. Last page in scan = 849.
Object ID for pages in this chain = 1148528094.
End of chain reached.
Page : 1397
Page : 1398
Page : 1399
Page : 1400
Page : 1401
Page : 1402
Page : 1403
Page : 1404
Page : 1405
Page : 1406
Page : 1407
Page : 1408
Page : 1409
Page : 1410
Page : 1411
15 pages scanned. Object ID = 1148528094. Last page in scan = 1411.Nous allons effectuer la récupération de la table à l'aide de la commande en ligne bcp, en y affectant le paramètre -b1 permettant de décharger la table ligne après ligne. Compte tenu de notre corruption, cette commande échouera lorsqu'elle atteindra la ligne fatidique.
bcp test..PERSONNE out Fichier1.bcp -c -b1 -Usa -Pxxx
Starting copy...
1000 rows successfully bulk-copied to host-file.
2000 rows successfully bulk-copied to host-file.
3000 rows successfully bulk-copied to host-file.
4000 rows successfully bulk-copied to host-file.
5000 rows successfully bulk-copied to host-file.
6000 rows successfully bulk-copied to host-file.
7000 rows successfully bulk-copied to host-file.
...
[crash]Relevons que pour une table partitionnée, on pourra exécuter l'ordre par partition. Celui qui plantera déterminera la partition comprenant la page corrompue.
bcp test..PERSONNE:1 out Fichier1a.bcp -c -b1 -Usa -Pxxx -SMonAse
bcp test..PERSONNE:2 out Fichier1b.bcp -c -b1 -Usa -Pxxx -SMonAse
bcp test..PERSONNE:3 out Fichier1c.bcp -c -b1 -Usa -Pxxx -SMonAseMaintenant, nous déplaçons le curseur du début de la table sysindexes (ou syspartitions si la table est partitionnée) sur la page suivant la page corrompue. Puis nous redémarrons le serveur afin de rafraîchir les données se trouvant dans la structure mémoire DBINFO. Il n'existe malheureusement aucune commande permettant de le faire sans redémarrer le serveur :
exec sp_configure "allow updates",1
go
update sysindexes set first = 1397
where indid = 0
and id = 1148528094
go
shutdown
goNous effectuons ensuite un second bcp out. L'option -b1 n'est plus nécessaire. Il va nous générer un fichier contenant la fin de la table.
bcp wsb..PERSONNE out Fichier2.bcp -c -Usa -Pxxx
Starting copy...
1000 rows successfully bulk-copied to host-file.
1451 rows copied.
Clock Time (ms.): total = 1 Avg = 0 (451000.00 rows per sec.)Nous arrivons à la phase la moins agréable de l'opération: la récupération de la page corrompue. Nous allons éditer la page et exécuter les inserts à la main. Compte tenu du format retourné, il n'est pas toujours possible de le faire aisément. Si tel était le cas, essayez de récupérer suffisamment d'information afin de retrouver ces quelques enregistrements par un autre biais.
dbcc traceon(3604)
go
dbcc page (5, 1396,1,0)
go
Page read from disk.
BUFFER:
Buffer header for buffer 0x214C5000 (Mass head)
page=0x214C5800 bdnew=0x00000000 bdold=0x00000000 bhash=0x00000000
bmass_next=0x00000000 bmass_prev=0x00000000 bvirtpg=83887476 bdbid=5
bmass_head=0x214C5000 bmass_tail=0x214C5000 bcache_desc=0x2022A360
bpool_desc=0x00000000 bdbtable=0x00000000
Mass bkeep=0 Mass bpawaited=0 Mass btripsleft=0 Mass btripsleft_orig=0
bmass_size=2048 (2K pool) bunref_cnt=0
bmass_stat=0x0800 (0x00000800 (MASS_NOTHASHED))
bbuf_stat=0x0 (0x00000000)
Buffer blpageno=1396 bpg_size=2k Mass blpageno=1396(Buffer slot #: 0)
bxls_pin=0x00000000 bxls_next=0x00000000 bspid=0
bxls_flushseq=0 bxls_pinseq=0 bcurrxdes=0x00000000
Latch and the wait queue:
Latch (address: 0x214C5020)
latchmode: 0x0 (FREE_LATCH)
latchowner: 0
latchnoofowners: 0
latchwaitq: 0x00000000
latchwaitqt: 0x00000000
Latch wait queue:
PAGE HEADER:
Page header for page 0x214C5800
pageno=1396 nextpg=1397 prevpg=1395 objid=1148528094 timestamp=0000000132a0
nextrno=31 level=0 indid=0 freeoff=1969 minlen=42
page status bits: 0x101 (0x0100 (PG_ADDEND), 0x0001 (PG_DATA))
DATA:
Row-Offset table at the end of the row: (, , )
Offset 32 - row ID=0 row length=62 # varlen cols=2
214C5820 ( 0): 02000000 003e2143 656c6169 61202020 .....>!Celaia
214C5830 ( 16): 20202020 20202020 20202020 20202020
214C5840 ( 32): 20202020 20000000 01a33e00 46616269 .....>.Fabi
214C5850 ( 48): 656e3593 00004fd0 8a00033a 322c en5...O....:2,
Row-Offset table for variable-length columns:
[1, 44, 6] [2, 50, 8]
Offset 94 - row ID=1 row length=63 # varlen cols=2
214C585E ( 0): 02010000 003e2243 656c6169 61202020 .....>"Celaia
214C586E ( 16): 20202020 20202020 20202020 20202020
214C587E ( 32): 20202020 20000000 01a33f00 44616e69 .....?.Dani
214C588E ( 48): 656c6535 9300004f d08a0003 3b332c ele5...O....;3,
Row-Offset table for variable-length columns:
[1, 44, 7] [2, 51, 8]
[...]
Offset 1844 - row ID=29 row length=63 # varlen cols=2
214C5F34 ( 0): 021d0000 003e3e43 656c6169 61202020 .....>>Celaia
214C5F44 ( 16): 20202020 20202020 20202020 20202020
214C5F54 ( 32): 20202020 20000000 01a33f00 44616e69 .....?.Dani
214C5F64 ( 48): 656c6535 9300004f d08a0003 3b332c ele5...O....;3,
Row-Offset table for variable-length columns:
[1, 44, 7] [2, 51, 8]
Offset 1907 - row ID=30 row length=62 # varlen cols=2
214C5F73 ( 0): 021e0000 003e3f43 656c6169 61202020 .....>?Celaia
214C5F83 ( 16): 20202020 20202020 20202020 20202020
214C5F93 ( 32): 20202020 20000000 01a33e00 46616269 .....>.Fabi
214C5FA3 ( 48): 656e3593 00004fd0 8a00033a 322c en5...O....:2,
Row-Offset table for variable-length columns:
[1, 44, 6] [2, 50, 8]
OFFSET TABLE:
Row - Offset
30 (0x1e) - 1907 (0x0773), 29 (0x1d) - 1844 (0x0734),
28 (0x1c) - 1782 (0x06f6), 27 (0x1b) - 1719 (0x06b7),
26 (0x1a) - 1657 (0x0679), 25 (0x19) - 1594 (0x063a),
24 (0x18) - 1532 (0x05fc), 23 (0x17) - 1469 (0x05bd),
22 (0x16) - 1407 (0x057f), 21 (0x15) - 1344 (0x0540),
20 (0x14) - 1282 (0x0502), 19 (0x13) - 1219 (0x04c3),
18 (0x12) - 1157 (0x0485), 17 (0x11) - 1094 (0x0446),
16 (0x10) - 1032 (0x0408), 15 (0x0f) - 969 (0x03c9),
14 (0x0e) - 907 (0x038b), 13 (0x0d) - 844 (0x034c),
12 (0x0c) - 782 (0x030e), 11 (0x0b) - 719 (0x02cf),
10 (0x0a) - 657 (0x0291), 9 (0x09) - 594 (0x0252),
8 (0x08) - 532 (0x0214), 7 (0x07) - 469 (0x01d5),
6 (0x06) - 407 (0x0197), 5 (0x05) - 344 (0x0158),
4 (0x04) - 282 (0x011a), 3 (0x03) - 219 (0x00db),
2 (0x02) - 157 (0x009d), 1 (0x01) - 94 (0x005e),
0 (0x00) - 32 (0x0020),Nous allons maintenant supprimer la table corrompue. Pour ce faire, il nous faut modifier à nouveau la table sysindexes (ou syspartitions, si la table est partitionnée) afin de lui redonner ses valeurs originelles et … redémarrer le serveur.
update sysindexes set first = 135976 where indid = 1 and id = 816005938
go
shutdown
goPetite astuce dans le cas de l'utilisation de Sybase ASE (dès sa version 11.9.2) : si vous avez la chance d'avoir vos statistiques à jour et non corrompues, il se peut qu'il vous soit encore possible de retrouver le nombre d'enregistrements de votre table avec la commande suivante :
SELECT rowcnt
FROM SYSTABSTATS
WHERE id = OBJECT_ID("PERSONNE")
AND indid IN (0,1)En fin de procédure de récupération, vous comparerez la valeur obtenue avec un
SELECT count(*)
FROM PERSONNEappliqué sur votre table réparée. Cette information doit être considérée réellement comme indicative, car lors de corruptions avérées de base, les statistiques ne sont pas toujours épargnées.
Supprimons ensuite la table en la tronquant avant tout. N'utilisez surtout pas la commande delete qui générerait à nouveau la corruption. Si la table est partitionnée, la départitionner d'abord afin de faire passer l'ordre truncate table.
truncate table PERSONNE
go
drop table PERSONNE
goAfin de ne pas recréer la table sur un fichier qui pourrait être encore corrompu, nous allons déterminer le fichier causant problème afin de l'éviter.
use master
go
select name , lstart, low, high
from sysdevices, sysusages
where dbid=5
and vstart between low and high
and lstart =
(select max(lstart)
from sysusages, sysdevices
where dbid=5
and vstart between low and high
and lstart <1396)
go
name lstart low high
--------- ------ ---------- -----------
data1 0 83886080 83896319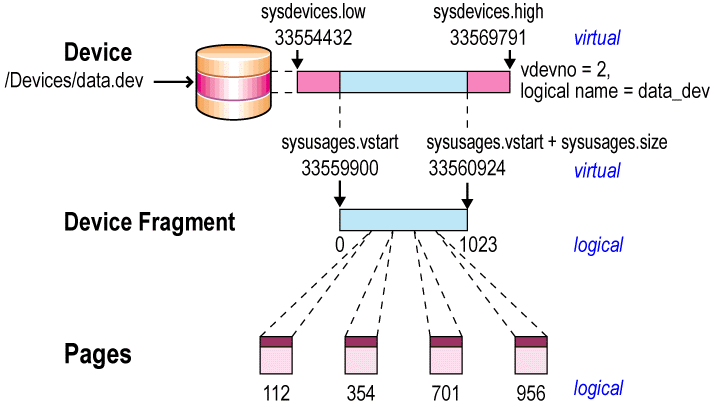
Le fichier ayant été ainsi trouvé, nous allons copier les objets qui lui sont attribués sur un autre fichier. Pour cela, nous allons utiliser le mirroring de Sybase.
disk mirror Name=data1, mirror ="c:\data\MonNouveauDevice.dat"
go
disk unmirror name=data1, side="primary", mode=remove
goRecréons maintenant la table, mais sans les index, ceci afin d'autoriser le chargement rapide via bcp
Create table PERSONNE (...)Chargement des deux fichiers générés précédemment, puis insertion manuelle des données découvertes précédemment
bcp test..PERSONNE in Fichier1.bcp -c -Usa -Pxxx
bcp test..PERSONNE in Fichier2.bcp -c -Usa -PxxxRécréation des index manquants
Create unique clustered index on ADRESSE(ID)
Create nonclustered index on...
goSauvegarde de la base de données, après avoir testé son intégrité à l'aide des commandes usuelles dbcc checkdb, dbcc checkalloc, dbcc checkcatalog, dbcc checkstorage (pas sous MS-SQL)
V. Conclusion▲
Si vous m'avez suivi jusqu'ici, vous aurez compris qu'une bonne stratégie de sauvegarde ou de réplication reste la méthode la plus simple et la plus rapide pour s'en sortir lors de corruptions.
J'ajouterai cependant qu'il existe certains programmes permettant d'aller encore plus loin dans la décorruption de bases en permettant l'édition et la modification des pages (Sybedit utilisé par le support technique de Sybase). Bien plus encore que la procédure que vous venez de suivre, ils demandent de la prudence et de l'expertise afin que le médicament ne devienne pas pire que le mal.
Historiquement, le traceflag -T 4011 permettait d'accéder à un menu caché qui permettait de le faire, mais il a été désactivé dans les versions actuelles.