





I. Introduction▲
Avec l'augmentation des volumes des données, la montée en charge des utilisateurs sur les SGBDR la demande de haute disponibilité, et la différence de coût entre hosts et petits systèmes, la mise en réseau d'une base de données devient une demande grandissante du marché.
Quelques éditeurs offrent déjà un certain nombre de solutions, avec plus ou moins de bonheur.
Si les bases de données se ressemblent plus ou moins toutes en ce qui concerne leur interface (norme SQL), des fonctionnalités backoffice telles que la clusterisation diffèrent énormément d'un éditeur à un autre.
Voici donc un petit comparatif qui vous permettra de voir plus clair dans ces nouveaux concepts.
Dans cet article ne sont pas abordées les notions :
- de cluster via système d'exploitation qui consistent à virtualiser 2 machines en une (SQL Server cluster pré 2005, Oracle Fail Safe) ;
- de solutions fail-over / warm-standby gravitant au niveau des réplications diverses.
Le marché s'oriente résolument vers des architectures Blade (fermes de PC) sur Linux (Suse Enterprise ou RedHat Advanced Server), en s'appuyant sur
- leur stabilité ;
- leur faible coût d'investissement ;
- leur reconnaissance de la part de la plupart des éditeurs de SGBDR ;
- un système d'exploitation 64 bits ;
- une gestion de mémoire optimisée même au-delà des 3 Go… ;
- un tuning de disques fin (asynchronous IO).
II. La problématique et les challenges▲
Avant tout, à quoi sert le clustering ? Cette idée vient du concept de Grid, ou virtualisation des ressources, déjà utilisé dans des projets tels que le Seti.
Un SGBDR est une application gourmande en mémoire, en disques et en CPU. Sur le marché, les gros serveurs (mainframe) sont fortement coûteux, tandis que de petites machines sont relativement peu onéreuses. Il faut donc trouver un moyen de fédérer ces petites machines afin qu'elles réagissent comme une grosse.
Comme vous le verrez rapidement, un des challenges du grid reste entier, quelle que soit la stratégie choisie et quel que soit l'éditeur : celui de la virtualisation des diverses mémoires. À qui le premier ?
III. Les stratégies▲
III-A. Ne rien partager (share nothing)▲
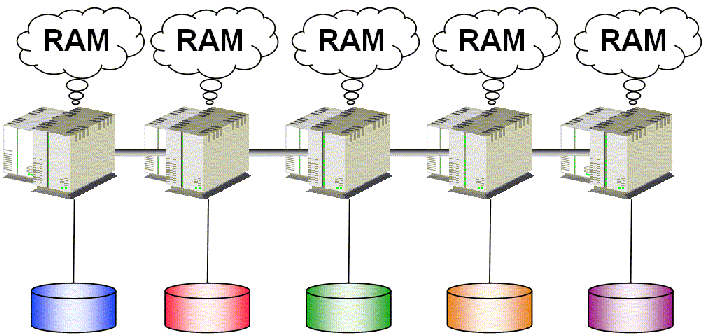
C'est la stratégie utilisée par IBM DB2-UDB EEE
DB2-UDB EEE se base sur une technologie share-nothing, ce qui n'en fait techniquement pas une base cluster, mais plutôt une base distribuée.
En environnement EEE (cluster), la conception de l'accès aux données n'est pas totalement transparente pour le développeur : écrite sans suivre des lignes bien précises, des applicatifs peuvent se retrouver à n'utiliser qu'un nœud majeur, au détriment de toute la plateforme.
Cette architecture convient à des applications aisément sécables, mais peut fortement péjorer les performances des requêtes qui ne suivraient pas les clés de répartitions choisies lors des partitionnements.
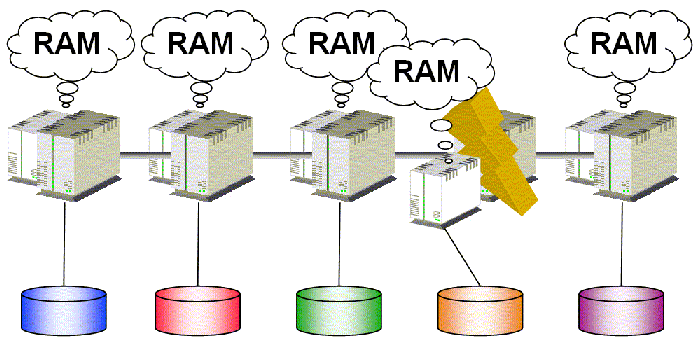
Pour gérer de manière « plus transparente » les nœuds, il est nécessaire de se baser sur la couche cluster de l'OS pour gérer le contrôle de validité des nœuds (heartbeat).
Lors de la chute d'un nœud, on perd momentanément l'accès à ses données tant qu'un autre nœud ne reprend pas la main sur elles. Pour que cette reprise ait lieu, il faut donc
- travailler avec des disques partagés (!) afin qu'une instance secondaire située sur une autre machine puisse prendre le relais ;
- mettre son instance secondaire sur la même machine (!) que la primaire pour ne pas utiliser de disques partagés.
Relevons que pour pallier certaines de ces faiblesses, IBM offre une solution - Parallel Sysplex - orientée… disques partagés…
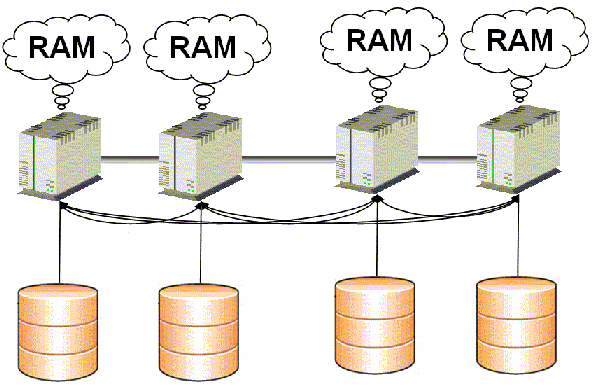
III-B. Tout dédoubler (share nothing with replication)▲
C'est la stratégie utilisée par MySQL, développée par Ericsson : chaque nœud comprend la totalité de l'information du système. Il semblerait que le pgCluster de PostgreSQL se base sur les mêmes principes.
La synchronisation des données se fait via un mécanisme de réplication interne, et en mode synchrone. Tout se réplique sur tout, ce qui laisse présager quelques soucis avec un nombre de nœuds important…
Ce choix étrange est fortement prétéritant pour les performances, mais c'est le prix de la sécurité pour une technologie essentiellement orientée fail-over.
Répliquer l'information autant de fois qu'il y a de nœuds est de plus fortement coûteux en terme de disques (pour n Go de données et m nœuds, il faut avoir n*m Go de disque )et en terme de CPU (toutes les transactions OLTP se jouent sur tous les nœuds).
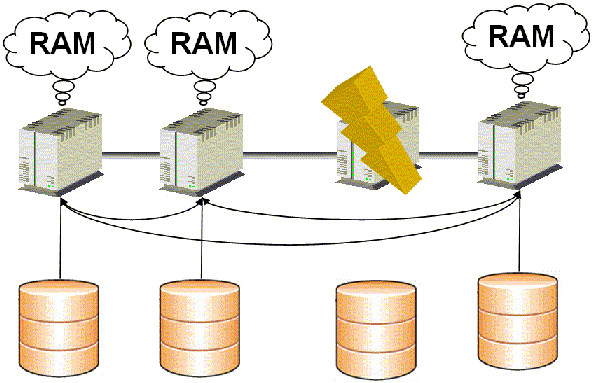
Il va sans dire que cette solution marche à merveille lors d'une quelconque perte d'instance, tout étant répliqué partout.
III-C. Partager les disques (shared disks)▲
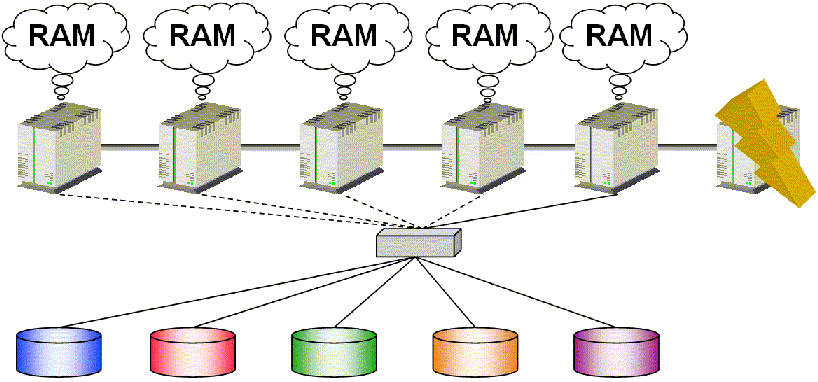
C'est la stratégie utilisée par Sybase ASE : une base est visible et utilisable par toutes les instances, mais seule une instance gère toutes les modifications.
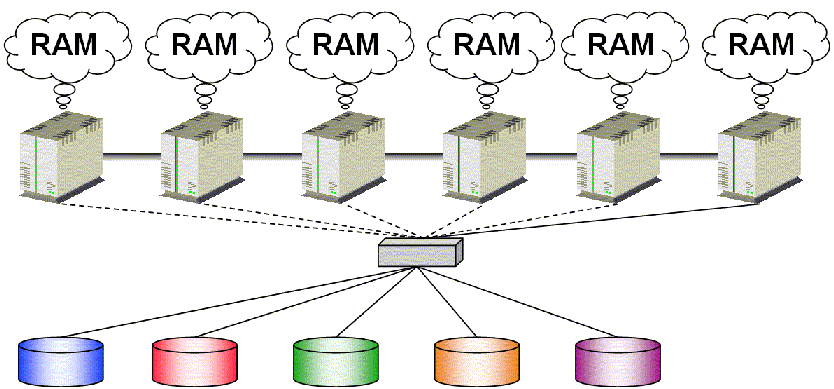
En cas de crash d'une instance, c'est une autre instance qui transforme sa base Proxy (remote) en base locale.
III-D. Partager disques et mémoire (shared disks with cache fusion)▲
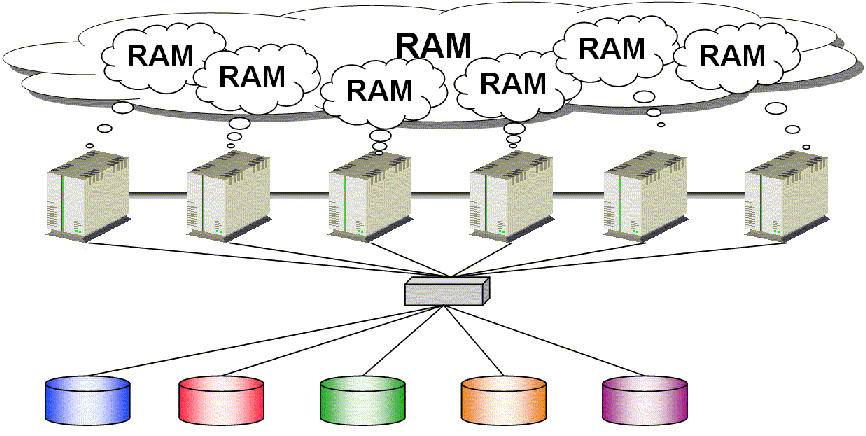
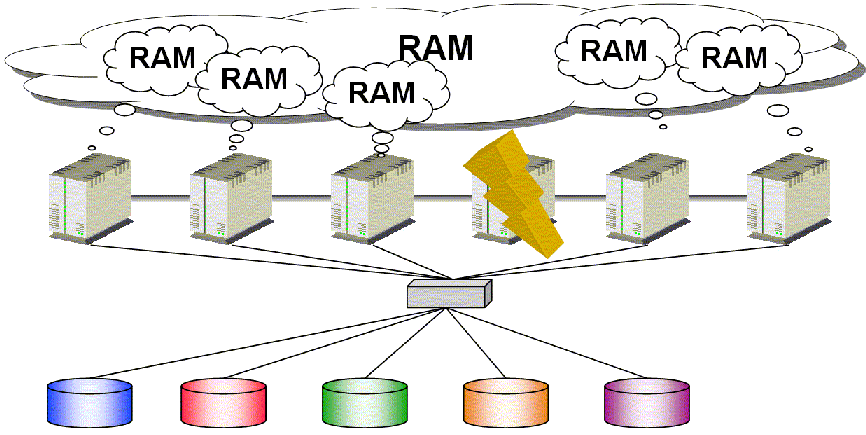
C'est la stratégie utilisée par Oracle RAC : chaque nœud peut accéder à la totalité de l'information du système
Oracle offre enfin un environnement cluster digne de ce nom. Il s'appuie sur une technologie RAC de disques partagés, ce qui fait que chaque instance Oracle voit et utilise les mêmes données.
L'intérêt de cette technologie est sa transparence quasi totale : aucune spécificité n'est à gérer dans le code et le passage « Oracle simple instance » à « Oracle RAC » ne nécessite aucun changement au niveau du développement. Il faudra par contre, au niveau DBA, passer par une recréation de base + full export/import.
C'est un sous-système Oracle qui gère intelligemment la notion de verrous et de synchronisation de blocs mémoire, permettant ainsi l'utilisation simultanée d'une donnée par plusieurs instances.
Lors de la chute d'un nœud, on ne perd pas d'accès aux données et on continue à travailler en mode dégradé (avec un TAF bien réglé, cela s'entend).
IV. Résumé du comparatif▲
|
Stratégie |
Tout dédoubler |
Ne rien partager |
Partager les disques |
Partager disques et mémoire |
|---|---|---|---|---|
|
Éditeur |
||||
|
Disponibilité jusqu'au dernier nœud |
OUI |
NON |
OUI |
OUI |
|
Transparence au design |
OUI |
NON |
OUI |
OUI |
|
Indépendance des instances |
OUI |
NON |
NON |
OUI |
|
Volumétrie non duplifiée |
NON |
OUI |
OUI |
OUI |
|
Écriture d'un bloc de données via plusieurs nœuds |
OUI |
NON |
NON |
OUI |
|
Performance / montée en charge |
NON |
OUI |
NON |
OUI |
|
Interréplication nécessaire |
OUI |
NON/OUI |
NON |
NON |
|
Synchronisation disques/mémoire |
Réplication |
Distribution |
Base proxy |
Fusion mémoire |
|
Intégration à un existant |
Plug-In |
Reload / split |
Plug-In |
Plug-In |
|
Tuning fin nécessaire sur partitionnement |
NON |
OUI |
NON |
NON |
|
Convient pour grand nombre de nœuds |
NON |
OUI |
OUI |
OUI |
|
Unicité nécessaire dans chaque table |
NON |
OUI |
NON |
NON |
|
Open source |
OUI |
NON |
NON |
NON |
Microsoft ne propose toujours pas de version en vrai cluster au niveau de la base: sa technologie s'appuie sur le cluster Windows et permet une quasi haute disponibilité en remontant plus ou moins rapidement une instance dont le nœud serait tombé sur un nœud sain. Cela reste de l'actif/passif… bien éloigné de ce que proposent ses concurrents.