





I. Introduction▲
Issue de l'époque lointaine (au moins 10 ans !) où il n'était pas aisé de faire cohabiter une grosse masse d'informations sur de nombreux raw devices, ventilés sur de non moins nombreux disques, la gestion des fichiers de donnée sous Sybase ASE peut paraître quelque peu complexe au néophyte.
Le prix à payer à ce jour est une mauvaise compréhension de la complexité de la gestion des espaces de stockage du DBA Junior, et la mécompréhension de l'inexistence de deux spécificités présentes déjà dans d'autres SGBDR :
- L'inexistence d'une clause AUTOEXTENT lors de la création de devices (cf. autre article du même auteur) :
- L'incapacité de réduire la taille d'un device ayant été trop largement taillé.
Cet article a pour but d'apporter une solution à la soi-disant impossibilité de réduire un device sous ASE.
II. L'explication historique▲
Sybase ASE (anciennement Sybase SQL Server) permettait en fait de définir avant tout ses espaces de stockage, puis ensuite de tailler dans lesdits espaces les segments nécessaires à chaque base de données.
Il faut garder en mémoire que jusqu'en version 11.9, le seul système de stockage supporté en production était le raw device. Il permettait d'assurer une intégrité des accès disques à ASE (en évitant tout cache OS). Ce raw device était généralement créé par l'administrateur système, et non pas par l'administrateur de la base. Une fois cet espace créé, sa taille ne pouvait varier… ce qui explique que l'autoextension ou la réduction du fichier ne pouvait être une option au niveau de l'instance ASE.
Nous avions donc une application claire de ce que Codd souhaitait : une dissociation claire et nette de la partie logique (base de données, tables) et de la partie physique (devices, fichiers sur disques…).
Ce qui différencie donc ASE de la plupart de ses concurrents, et ce qui explique certaines contraintes, c'est que l'on y crée des devices neutres. Ce n'est qu'à l'affection de zones que l'on détermine leur contenu, et que le contenu peut être variable. C'est d'ailleurs pour cela que le stockage des informations sur les devices se fait dans la table sysdevices de master, puis que c'est ensuite une table de liens master..sysusages qui stocke le partage des devices de sysdevices avec les dbid de sysdatabases.
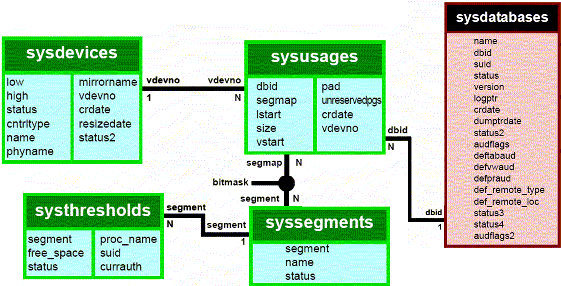
Microsoft a cassé cette logique dès la version 2000 en rapatriant les informations de stockage dans la base elle-même, et en dissociant fortement les fichiers de données (.mdb) et ceux du journal de transactions (.ldb).
Afin d'éviter d'éventuels verrouillages et des accès disques très prétéritants sur les tables système, le métamodèle de Sybase ASE a toujours tenté de rester le plus normalisé possible. Pour des raisons de performances, l'engineering de Sybase s'est toujours fait un devoir de minimiser les accès sur ces tables. Une insertion dans une table, tant qu'elle ne modifie pas un index, ne provoquera quasi pas d'écriture dans le métamodèle.
C'est pour cette raison principale que vous ne trouverez pas, comme chez Oracle avec sa vue DBA_SEGMENTS, une liste référençant l'adresse de toutes les pages allouées pour un objet. Sous ASE, tout est chaînage de pages. Dans les tables systèmes, et principalement dans sysindexes, ne sont stockées que quelques informations concernant l'adressage du début du chaînage. Si l'on souhaite obtenir des informations sur le chaînage complet d'un objet, ce sont des outils lents et gourmands tels que dbcc page, dbcc pglinkage … qu'il faut alors utiliser.
Cet état de fait est la raison pour laquelle le rétrécissement d'un segment, et de fait d'un device, n'est pas quelque chose de supporté sous ASE.
Pour réduire un device en dessus de ce qui lui est alloué, il « suffit » de mettre sa valeur high à la valeur souhaitée. Si des segments lui sont déjà attribués, il faudra avant tout aller vider ces segments… ou s'assurer qu'ils soient vides… avant de corriger dans sysusages.
III. Réduction de la taille d'un device▲
Comme je l'ai spécifié plus haut, c'est la table master..sysusages que nous allons devoir traiter ici.
Il faut envisager, pour un dbid spécifique et par ordre de lstart, les couches de segments comme des couches d'un sandwich.

- Il est possible de compacter deux couches conjointes de même nature.
- Il est possible de supprimer une couche supérieure du sandwich si elle ne contient rien.
- Il n'est pas possible de modifier une couche ayant hébergé un segment system.
Comme vous pouvez le voir plus haut dans les tables systèmes, depuis la version 15, le lien entre sysusages et sysdevices ne se fait plus sur la liaison vstart between low and high, mais directement sur une clé vdevno (le low étant à 0). Selon votre version, vous aurez donc besoin de corriger ce qui suit par conséquent.
La procédure stockée sp_helpdb ne nous renseigne que partiellement puisqu'elle ne fait le distinguo qu'entre data et log segments.
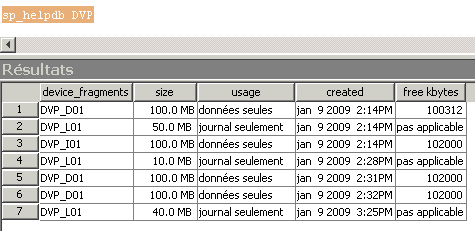
Afin de déterminer le contenu en segments d'un fragment de fichier, il faut se baser sur la colonne master..sysusages.segmap qui est un masque de bits et sur la table syssegments de chaque base.
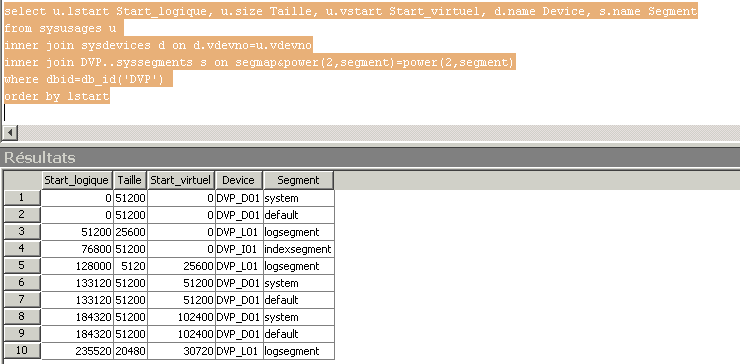
Notons la clause de jointure entre syssegments et sysusages qui permet de détecter quel segment se trouve sur quel fragment de device.
Relevons que par choix, nous avons laissé le segment system avec le segment data… puisque nous n'utilisons qu'un seul device spécifique pour ces deux types de segments.
Notons enfin que la représentation tabulaire par segment pourrait nous induire en erreur puisque les deux premières lignes ne représentent en fait qu'un device comprenant deux segments.
Faisons fi de la couche la plus haute de journal et imaginons-nous ces fameuses couches en sandwich. Nous aurions donc :

Dans le premier cas, il est aisé de coupler 2 segments de même nature puisque nous sommes en mesure de déterminer très clairement qu'ils appartiennent au même device et qu'ils sont conjoints


En effet, l'adresse de start logique est dans notre exemple à 133120 et la taille du segment est de 51200. Le départ de l'adresse logique suivante est à 184320 = 133120+51200. On est donc certain qu'aucun segment intercalaire n'existe.
On peut donc sans autre effectuer la modification suivante directement dans la sysusages, ceci étant bien entendu totalement non supporté officiellement par Sybase.
use master
exec sp_configure "allow update",1
begin tran
-- Modifications
update sysusages set size=102400 where lstart=133120 and dbid=db_id('DVP')
delete sysusages where lstart = 184320 and dbid=db_id('DVP')
-- Contrôle
select * from sysusages where dbid=db_id('DVP')
-- Validation (ou rollback au cas où !)
commit
exec sp_configure "allow update",0
use DVP
dbcc traceon(3601)
dbcc checkcatalog
select @@error
Ce traitement n'a pas réellement de plus-value, hormis de prouver sa faisabilité et de supprimer la trace du disk remap.
Le chaînage des tailles et des adresses logiques explique aussi pourquoi il n'est pas aisé de réduire la taille d'un device. On peut « sans autre » (après avoir déterminé qu'aucun objet ne se trouve dans la partie à tronquer) réduire la taille d'un segment, mais il n'est pas possible de réduire la taille du fichier associé via des commandes T-SQL (on peut toujours le faire à ses risques et périls via une petite routine C insérant un EOF à une adresse donnée).
Nous allons maintenant supprimer le segment. Pour ce faire, nous devons être certains que plus aucun objet ne se trouve dans la tranche que nous voulons supprimer.
Commençons par le bout de journal se trouvant tout au sommet de notre sandwich. Pour tronquer un journal, il suffit de s'assurer que toutes les transactions sont fermées, puis de lancer une opération de troncature.

select * from master..syslogshold where dbid=db_id('DVP')Si cette requête ne retourne pas de ligne, c'est qu'il n'y a pas de transactions ouvertes sur la base DVP, soit le cas que nous souhaitons.
Nous pouvons dès lors tronquer le log et supprimer le haut du sandwich, à savoir :
use master
dump tran DVP with truncate_only
use DVP
checkpoint
use master
exec sp_configure "allow updates",1
begin tran
-- Modification
delete sysusages
where dbid = db_id('DVP')
and lstart=(select max(lstart) from sysusages where dbid = db_id('DVP') and segmap=4)
-- contrôle
select * from sysusages where dbid = db_id('DVP')
-- Validation
commit
exec sp_configure "allow updates",0
use DVP
dbcc checkcatalog
select @@error
dbcc checkdb
select @@error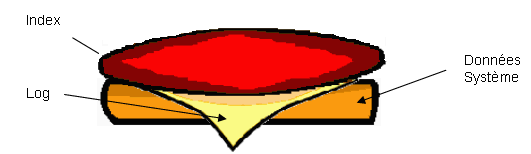
Dans le cas d'une base de données répliquée, il y a deux points de troncature. Celui, standard, de la dernière transaction fermée, et celui plus ancien de la dernière transaction fermée et répliquée. C’est cette dernière qui fait foi, mais cela ne devrait pas vous poser problème, le DUMP TRAN refusera de tronquer plus base.
Nous allons attaquer maintenant la réduction du device d'index. Nous nous basons sur ce que nous avons appris auparavant sur deux blocs contigus de même nature. Nous pouvons donc sans autre couper notre segment d'index en 2 (pour cet exemple, deux blocs de taille similaire, à savoir 50 Mo chacun). Nous en profitons pour invalider le 2e bloc en lui supprimant tout segment (segmap à 0).
use master
exec sp_configure "allow update",1
begin tran
-- Modifications
update sysusages set size=size/2 where lstart=128000 and dbid=db_id('DVP') -- Division de la taille par 2, de 100Mo (51200) à 50Mo (25600)
insert into sysusages values(db_id('DVP'),0, 128000+25600, 25600, 0, null, getdate(), 15) -- Insertion du 2e bloc
-- contrôle
select * from sysusages where dbid = db_id('DVP')
-- Validation
commit
exec sp_configure "allow update",0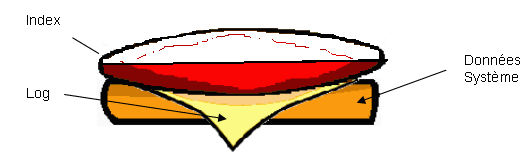
Que cela soit bien clair : en ce moment, le segment « blanc » du haut n'est plus allouable, mais les pages d'index initiales y sont toujours stockées. Il nous faut donc les déplacer dans la partie vive du bas.
Ceci ne peut se faire via un sp_placeobject, cette procédure ne déterminant que l'allocation future pour un objet donné. Il est donc nécessaire de reconstruire les objets du segment.
- Pour un segment de données, nous passerons donc par un bcp out/bcp in ou un sp_rename + select into OU par la recréation de son index cluster (s'il en existe un) ;
- Pour un segment d'index (notre cas précis), par une suppression et une recréation d'index (l'export du DDL pouvant se faire via l'utilitaire ddlgen ou des programmes plus robustes de type PowerAMC).
Lorsque le déplacement aura été fait, il nous suffira de supprimer la partie « morte » du segment
use master
exec sp_configure "allow update",1
-- Modification
begin tran
delete sysusages where dbid=(db_id('DVP') and segmap=0
-- contrôle
select * from sysusages where dbid = db_id('DVP')
-- Validation
commit
exec sp_configure "allow update",0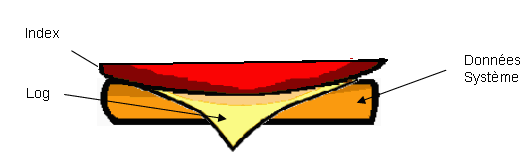
Afin de déterminer quel objet se trouve dans le segment en question, vous pouvez sans problème requêter sur colonne segment de la table système syspartitions (avant la version 15, sur sysindexes).
Vous comprenez sans doute la raison pour laquelle il n'est pas aisé de supprimer un morceau au milieu du sandwich: la partie supprimée laisserait un trou béant difficile à colmater par la suite. Difficile, mais pas impossible : il sera toujours possible de faire coïncider l'adresse de début du bloc mort avec une adresse sommitale d'un autre sandwich = d'une autre base…
IV. Conclusion▲
Comme vous l'avez sans doute remarqué, la procédure est loin d'être triviale. Elle a cependant le mérite d'exister. L'autre option moins élégante, mais supportée passe par la recréation d'une base de données et une régénération de tous ses objets. Il reste cependant des cas à forte volumétrie ou à haute disponibilité où cette méthode ne peut malheureusement être applicable.
V. Références▲
- Diagramme des tables systèmes de Sybase ASE
- Documentationde Sybase ASE