





I. Introduction▲
La synchronisation des données a toujours été un problème dans l'histoire de l'informatique en général, et des SGBDR en particulier. La normalisation des modèles a apporté une solution en l'évitant au maximum, l'information ne devant se trouver qu'à un seul endroit.
Mais il y a théorie et pratique : souvent, il est nécessaire de répliquer de l'information. Les bonnes raisons pour le faire sont nombreuses :
- dénormalisation pour des questions de performances ;
- distributions géographiques, décentralisation ;
- récupération de données d'autres environnements, centralisation ;
- sécurisation, sites de secours distants ;
- etc.
Ce petit document a pour but de vous faire appréhender la notion de réplication dans son sens large.
Il est basé sur le moteur Microsoft SQL Server 2005, car celui-ci offre plusieurs types de réplication et permet de les activer aisément.
Le dernier chapitre traitera des réplications sur d'autres types de SGBDR.
II. Réplications basiques▲
II-A. Par codage client▲
Avantages
- Pas besoin de compétences particulières.
- Pas besoin de ressources particulières.
- Codage dans l'applicatif, en spécifiant systématiquement deux sources de connexion.
- Pas de latence.
Inconvénients
- Pas du tout transparent pour l'applicatif.
- Une modification par n'importe quelle autre connexion désynchronise les données.
- Maintenance lourde : toute modification du modèle nécessite la recompilation de l'applicatif ou du composant métier.
- Désynchronisations, erreurs et pas de reprise et de resynchronisation lorsqu'une des sources et inatteignable.
- Pas conseillé pour une réplication à multi-instance.
- Temps de tout traitement multiplié par le nombre de cibles.
sqlcmd -E -S MSQLD1
1> begin tran
2> insert into DBSource1..MaTable (id, nom) values(1, "Repli Test 1")
3> insert into MSQLD2.DBCible1.dbo.MaTable (id, nom) values(1, "Repli Test 1")
4> goII-B. Par procédures stockées▲
Similaire sur le fond au codage client, cela permet de déplacer la problématique des connexions de l'applicatif à SQL Server.
Avantages
- Pas besoin de compétences particulières en réplication, mais nécessite de la programmation T-SQL.
- Pas besoin de ressources particulières.
- Codage hors applicatif, transparent pour l'application.
- Pas de latence.
Inconvénients
- Une modification par n'importe quelle autre connexion ou par accès direct aux tables sans passer par la procédure stockée désynchronise les données.
- Désynchronisations, erreurs et pas de reprise et de resynchronisation lorsqu'une des sources et inatteignable.
- Pas conseillé pour une réplication à multi-instance.
- Temps de tout traitement multiplié par le nombre de cibles.
sqlcmd -E -S MSQLD1
1> create procedure DBSource1..MaTable_ins (@i int, @v varchar(30))
2> as
3> BEGIN
4> declare @ret1 int
5> Begin tran
6> insert into DBSource1..MaTable (id, nom) values(@i, @v)
7> select @ret1 = @@error
8> insert into MSQLD2.DBCible1.dbo.MaTable (id, nom) values(@i, @v)
9> select @ret1 = @ret1 + @@error
10> if @ret1 > 0
11> rollback tran
12> else
13> commit
14> END
15> GO
1> exec MaTable_ins (1, "Repli Test 1")
2> goII-C. Par déclencheurs▲
Avantages
- Pas besoin de compétences particulières en réplication, mais nécessite de la programmation T-SQL.
- Codage hors applicatif, transparent pour l'application.
- Quelle que soit la source de la modification, le trigger se déclenche.
- Pas de latence.
Inconvénients
- Les triggers sont réputés peu performants.
- Nécessite le codage de trois triggers par table répliquée.
- Désynchronisations, erreurs et pas de reprise et de resynchronisation lorsqu'une des sources et inatteignable.
- Pas conseillé pour une réplication à multi-instance, ni multibase.
- Temps de tout traitement multiplié par le nombre de cibles.
sqlcmd -E -S MSQLD1 -D DBSource1
1> CREATE TRIGGER MaTable_ins_trig
2> ON MaTable FOR INSERT
3> AS
4> BEGIN
5> INSERT INTO MSQLD2.DBCible1.dbo.MaTable (id, nom)
6> SELECT id, nom FROM inserted
7> END
8> GO
1> CREATE TRIGGER MaTable_del_trig
2> ON MaTable FOR DELETE
3> AS
4> BEGIN
5> DELETE MSQLD2.DBCible1..MaTable WHERE id IN (SELECT id FROM deleted)
6> END
7> GO
1> CREATE TRIGGER MaTable_upd_trig
2> ON MaTable FOR UPDATE
3> AS
4> BEGIN
5> UPDATE MSQLD2.DBCible1..MaTable
6> SET T1.nom = T2.nom
7> FROM MSQLD2.DBCible1..MaTable T1 INNER JOIN inserted T2 ON T1.id = T2.id
8> END
9> GO
1> update MaTable set nom = "Test2" where id < 100
2> goII-D. Par Workflow▲
III. Réplications évoluées▲
À la réplication est toujours associé le terme de latence (latency) : il qualifie le temps qu'il faut pour qu'une information soit répliquée d'une source à sa cible.
Afin de pouvoir déterminer ce temps, nous allons, dans les exemples suivants, tenter de répliquer une table que nous nommerons repli_latence et qui aura les spécificités suivantes :
CREATE TABLE repli_latence (
ID int identity primary key
lastcommit datetime)
GO
insert into repli_latence values(1, getdate())
GOCette table ne comportera qu'une seule ligne par réplication.
Cette ligne sera updatée de manière régulière à la date et l'heure courante.
La comparaison entre les deux champs datetime dans les base source et cible nous donnera donc la latence.
III-A. Activation de la réplication▲
La documentation Microsoft vous apportera tout complément nécessaire au choix de réplication à mettre en place.
Quel que soit le type de réplication Microsoft que nous allons mettre en place, elle se base de toute manière sur une source de données. Chez Microsoft SQL Server, cette source est nommée une « Distribution ».
Dans Microsoft SQL Server Manager Studio, choisissons l'instance qui nous servira de source.
Directement sous le niveau de l'instance, un sous-répertoire « Réplication » est accessible.
Dans son menu contextuel, choisissons « Configure Distribution ».
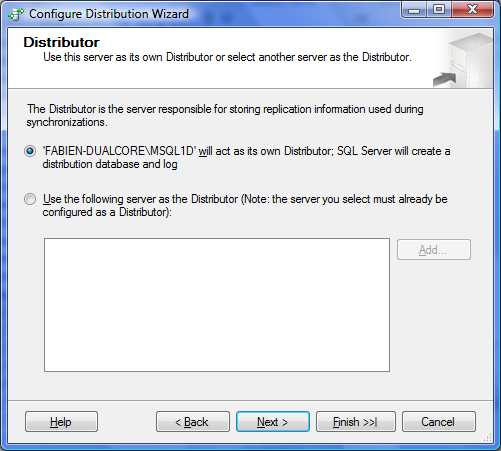
Nous choisissons donc la première option puisque nous sommes partis de l'instance source.
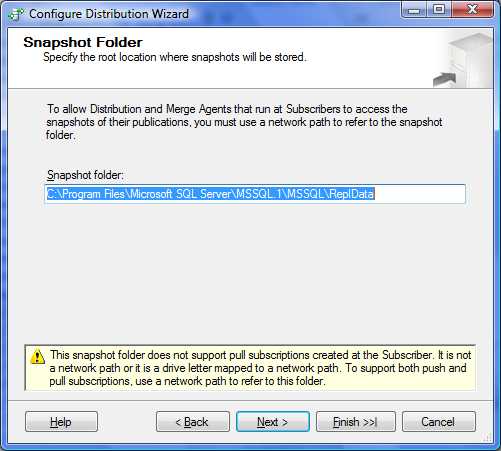
SQL Server va devoir créer un répertoire pour snapshot. Ce répertoire doit se situer sur la partie locale des disques de l'instance.
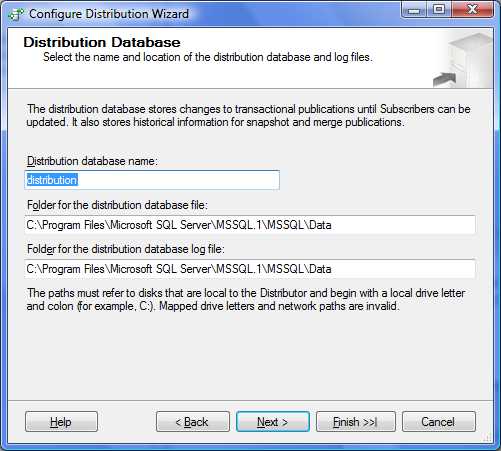
Microsoft SQL Server va alors créer la base de données système pour la réplication nommée « Distribution ».
Un dernier coup d'œil à nos choix avant que l'assistant ne démarre la phase d'installation de la base…
III-B. Réplication transactionnelle▲
La réplication transactionnelle, appelée aussi à flux tendu est le modèle le plus aboutit et répandu dans le monde du SGBDR, surtout pour la raison qu'elle est transactionnelle, et donc qu'elle maintient une intégrité transactionnelle au sein de la réplication.
Puisque chaque transaction répliquée passe en tant que transaction SQL, elle s'ouvre aux réplications hétérogènes, car il suffit alors de « transformer » la transaction pour qu'elle soit compatible avec les spécificités d'autres SGBDR.
La capture des modifications est alors faite au sein du journal des transactions.
Au moment où une transaction modifie une table marquée comme répliquée (publiée), elle est envoyée à la réplication qui s'occupera alors de l'exécuter sur les cibles « abonnées » (subscriber) à cette publication.
Exemple chez Microsoft et ses concurrents
- Réplication transactionnelle de Microsoft SQL Server
- Replication Server de Sybase (soit en mode Warm Standby, soit en mode Replication Definitions/subscriptions)
- Streams d'Oracle (avec logs ou archivelogs)
- Data Propagator chez IBM DB2-400
- …
III-C. Réplication par fusion▲
(merge) Les changements de la table sources sont relevés par triggers.
C'est une réplication idéale lorsque les souscripteurs sont nombreux et leurs connexions asynchrones.
Les demandes pouvant être asynchrones, cette réplication nécessite donc une gestion des conflits éventuels.
Si plusieurs modifications ont été apportées entre 2 réplications, seul le dernier état va être appliqué.
Exemple chez Microsoft et ses concurrents
- merge replication de Microsoft SQL Server ;
- SQL Remote de Sybase ;
- Job agendé + ordre MERGE avec Oracle ;
- …
III-D. Réplication par capture instantanée (snapshot)▲
Il s'agit là basiquement d'une réplication par copies chroniques.
À utiliser lorsque la latence entre source et cible peut être élevée.
Cette réplication influence peu en termes de performance la base source, même si les changements sont extrêmement fréquents. Il convient cependant de choisir le temps de latence intelligemment afin de ne pas péjorer les accès disques.